
GenAI development used to rely heavily on human-crafted rules and meticulously curated data. But that era is fading fast. Machines are now taking the wheel—building, evaluating, and refining the next wave of models with minimal human input. From generating their own training data to optimizing model architectures on the fly, this shift is accelerating innovation at a pace few could have predicted just a year ago.
These machine-driven techniques have exploded in recent months. While some may sound technical, the implications are clear: keeping up with these advancements is no longer optional. Falling behind while waiting for stability could prove immensely costly for most businesses. Sustainable money-making moats will no longer be through only idea generation - a point reflected through model makers like DeepSeek opting for radical transparency, forcing a re-think even for the closed-source champions like OpenAI. We will refrain from discussions on the impact we have covered before, and focus on the key developments.
Summary Table of Machines’ Rising Involvements
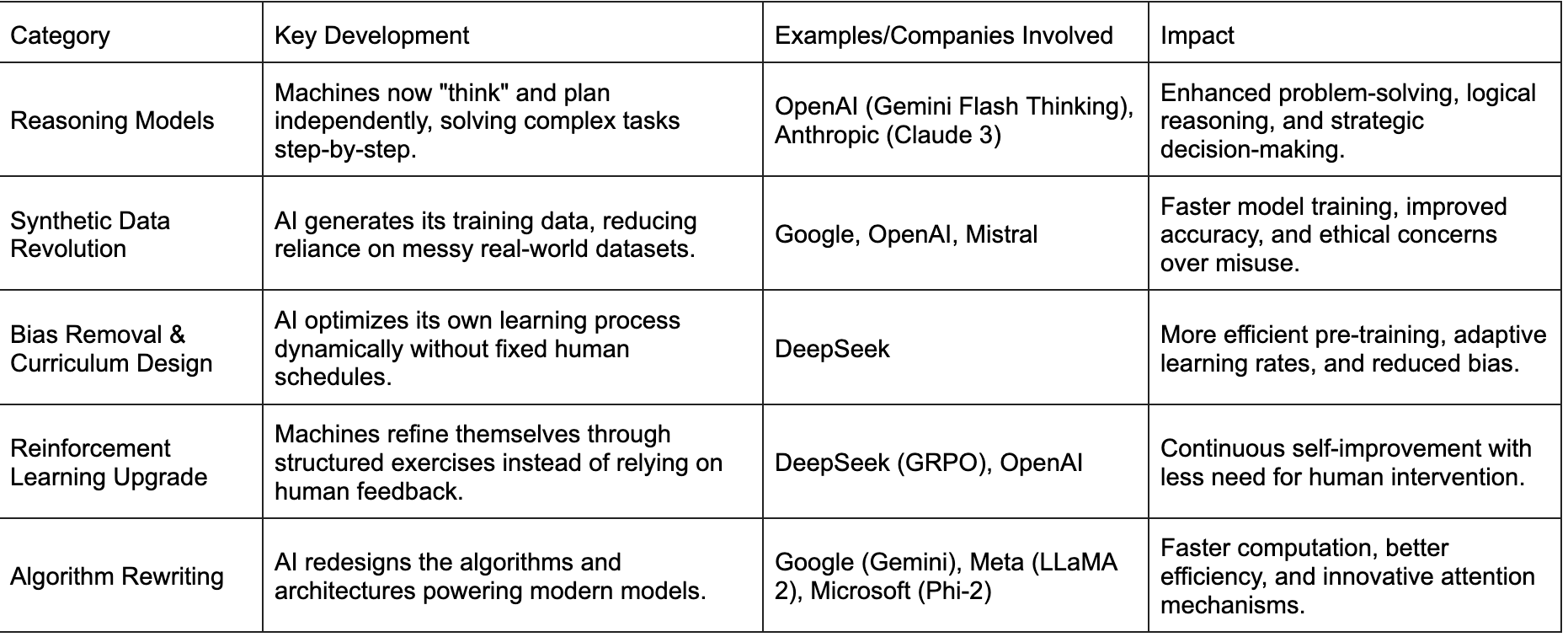
Reasoning Models: Machines Taking It Internal
The rise of reasoning models marks a seismic shift in artificial intelligence. These are not just machines that follow instructions—they think, adapt, and improve independently. A new breed of models from most reputed developers can now process information, draw inferences, make deductions, and even plan. These models have shown remarkable abilities in handling abstract concepts, long-form analysis, and multi-step reasoning. In its ways, models are not just regurgitating data; they behave as if they understand it.
They started barely a few months ago, but suddenly, they are everywhere. It was barely six months ago when Google and OpenAI announced their first reasoning models capable of thinking step-by-step. Just this week, OpenAI unveiled deep research capabilities that, at least at the announcement stage, resemble those previously revealed by Google or DeepSeek a few days or weeks ago. The simpler reasoning models from all these organizations have demonstrated enhanced contextual understanding, allowing them to interpret nuanced queries and deliver more coherent, logical responses. They continue to receive new names, such as Gemini Flash Thinking for the upgraded model announced this week. Anthropic’s Claude 3 Opus has shown a remarkable leap in reasoning capabilities, adeptly handling abstract concepts and long-form analysis with a level of sophistication previously unseen. In China, Qwen’s advancements pushed the boundaries even further with the announcement of Qwen Max last week.
As reasoning models evolve, their capabilities are no longer limited to static tasks. Their integration with external applications and systems is already underway, with AI models beginning to automate complex workflows, manage digital assets, and even make strategic decisions without constant human oversight. Agentic abilities are accelerating rapidly, primarily due to machines’ newfound capacity to internalize and deconstruct complex tasks into smaller steps.
The emergence of machines’ reasoning signals a quietly unfolding revolution that surprised many around mid-2024. One only needs to experiment with one of these models for research on standard subjects to appreciate the pace at which we progress. These models surpass all records in cognition and testing, albeit at the cost of a massive increase in inference computing—a topic for another discussion note.
The Synthetic Data Revolution: Bootstrapping Brilliance
For many, “synthetic data” carries an artificial, negative connotation. For others, it seems like the title of a complex topic. Imagine you are preparing for a math test, but instead of just using problems from your textbook, you create your own practice problems. That is essentially synthetic data—machine-generated information, not gathered from the real world. For systems like ChatGPT or Gemini, synthetic data includes text, code, or other information that AI produces to aid in training newer models.
The internet is full of messy, incorrect, or biased information. Synthetic data allows researchers to control its quality. Training an AI model typically involves gathering vast amounts of data from books, websites, and other sources. However, collecting and cleaning this data is time-consuming and costly. With synthetic data, AI can generate its own examples, reducing the time needed to prepare for training.
From Google to OpenAI, Mistral, and Grok, everyone is developing sharper, more efficient models created from the data distilled by their larger models. This has led to many models on each of these sites, which creates massive confusion for users on the one hand and a significant rise in the models’ capabilities.
The rise of synthetic data has also sparked some controversy. DeepSeek has been accused of using outputs from OpenAI and other models to train its own models. Whether this is legal is debatable, but it highlights a key point: AI-generated data is becoming incredibly valuable. It is so effective that companies might be tempted to bend the rules to acquire it.
Machines For Bias Removal: When AI Designs Its Curriculum
Traditionally, training an AI model involved a lot of human input. We decided what data to use, how to structure the training process, and how to evaluate the results. This stage is known as pre-training. As such, machines have been doing much more of that work for years. AI systems automatically select, organize, and even filter the data other AI models use to pre-train. Machine-driven pre-training optimization has improved steadily, and the latest advancements have taken it a notch higher.
In some ways, DeepSeek is leading to a rethink of how we train AI, as it allows the data to speak for itself. DeepSeek uses algorithms to adjust the learning parameters dynamically during pre-training. Instead of sticking to fixed schedules for how fast or slow the model learns (known as learning rates), their system allows the AI to fine-tune itself in real-time, depending on the complexity of the data it is processing. This adaptive approach means the model can focus more on complex concepts while breezing through simpler ones.
From Trial and Error to AI Tutor: Reinforcement Learning Gets an Upgrade
RLHF, or reinforced learning through human feedback has been a critical model development step with substantial human involvement. This is where we are witnessing the most meaningful machine takeover.
Instead of relying on human annotators to provide feedback on AI-generated answers, DeepSeek's Guided Reinforcement Pre-Optimization (GRPO) allows models to refine their reasoning abilities through structured, machine-generated problem-solving exercises. A key example is how AI systems now teach themselves mathematical reasoning—a skill that traditionally required human supervision to improve. Rather than having humans rank responses, DeepSeek’s models work through structured math problems, check their logic against pre-verified solutions, and adjust their reasoning pathways accordingly.
This shift toward machine-driven reinforcement learning is becoming a broader trend in AI development. OpenAI, for example, has begun training models on formal reasoning tasks, using structured math and logic exercises to refine problem-solving skills without human intervention. Google’s Gemini models have demonstrated similar improvements. The result is a dramatic acceleration in model improvement: where earlier AIs needed thousands of hours of human feedback, the new methods enable continuous learning without the same bottlenecks.
Machines Are Now Rewriting the Algorithms Themselves
Machines are not just learning language—they are improving the very algorithms that power modern models. Over the past few months, there has been a surge in the use of automated tools to optimize Transformer architectures, from adjusting equations to redesigning entire layers. This process, known as Neural Architecture Search (NAS), lets AI models experiment with different design choices to find more efficient or powerful structures. Google’s Gemini models have benefited from refining attention mechanisms and layer structures. Similarly, Anthropic’s Claude 3 has integrated machine-driven optimization to reduce computational overhead. Meta’s LLaMA 2 used machines to balance the load between different layers in the Transformer stack. Likewise, Microsoft’s Phi-2 model, released late last year, leveraged automated adjustments to its tokenization and embedding layers.
Even more fundamental mathematical changes are happening under the hood. Some recent models explore adaptive attention mechanisms, where the AI decides how much attention each part of the input deserves rather than using a fixed attention formula. This concept was implemented in Mistral’s latest models. In China, Alibaba’s Qwen introduced dynamic positional encoding, an adjustment to how transformers understand the order of words in a sentence. Hualao’s Minimax, on the other hand, has utilized machine-generated tweaks to improve feed-forward network efficiency.
These advancements highlight a growing trend: machines are no longer just students—they are becoming architects. AI systems are accelerating their development by automating the process of refining algorithms and architectures.
What Comes Next: Machines on Machines Fuel Rapid Innovation
There has been a remarkable increase in the pace of announcements from GenAI model developers in the last few weeks, and this is the first result of machines getting involved in the innovation process. They were supposed to hit a wall, and we are witnessing a deluge of new features and models from every player. So far, machines’ work is visible only in GenAI models’ improvements, but this is about to change. One should expect surprising twists and turns in areas like vision, biotech, drug discovery, and material science sooner rather than later.
Until now, we have only discussed generative AI methodologies’ impact on vision models and consequent new trends in Robotics or autonomous vehicles. As machines get involved, primarily in text-based models so far, one should expect multiple DeepSeek-like moments for multi-modal models in the coming months. One can easily extend these arguments to expect a completely different protein folding model or substantial new developments in almost any other field.
When machines generate ideas at a complexity level similar to or higher than our best scientists, the pace of innovation accelerates, and the chance of a new wave emerging from an unexpected corner, as long as someone is making an effort. The implications for anyone relying only on the power of ideas and idea-based products and features are not good. For sustainable, profitable businesses, staying in the innovation race will be a must, but differentiating through aspects that cannot be replicated and improved by rivals’ machines is equally important.
.png)

